Updates! LipSyncShow Now Supports Text To Speech And Recording

We are excited to announce a major update to LipSyncShow that makes creating AI lipsync videos even easier and more versatile. Previously, users could create lipsync videos by uploading a talking video and an audio file. Now, we have enhanced the tool by adding support for Text To Speech (TTS) and direct recording features within the audio options.
New Audio Options: Text To Speech and Recording
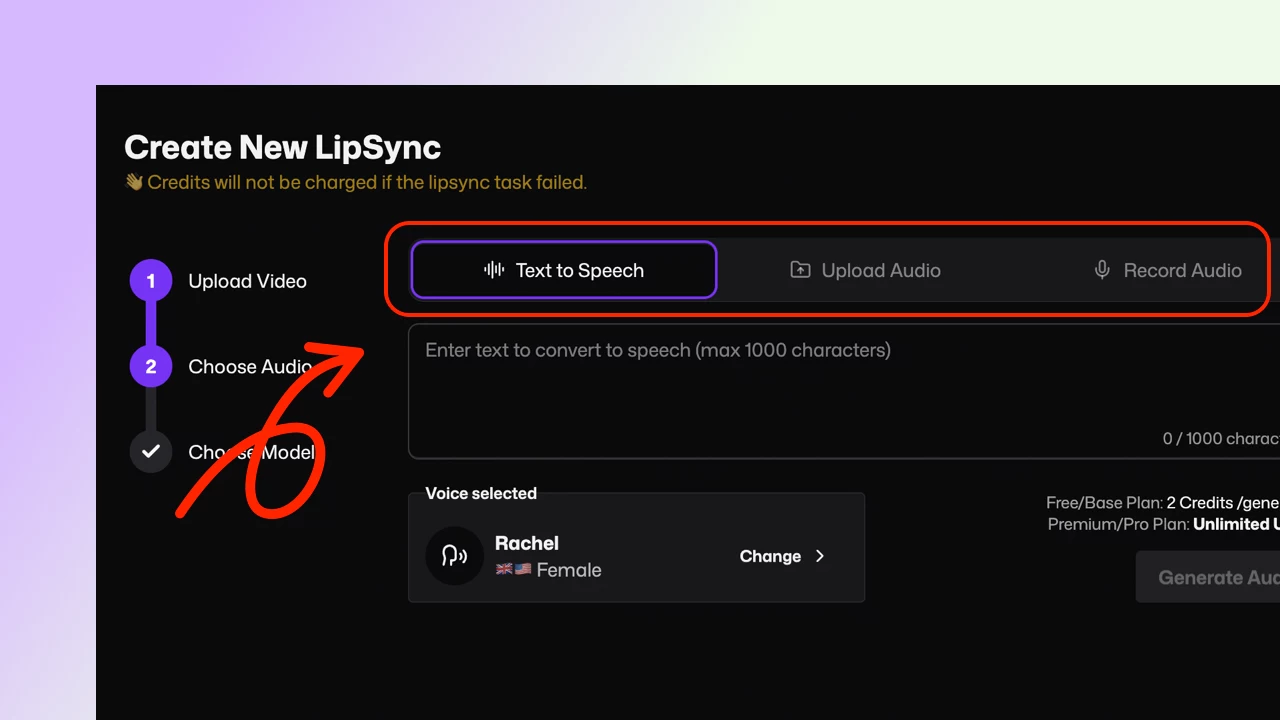
This new functionality means you no longer need to provide a separate audio file to generate lipsync videos. Instead, you can simply type your desired text and have it converted to speech using our integrated TTS engine, or record your voice directly on the site. This streamlines the process and opens up new creative possibilities.
Multiple Voice Choices

The Text To Speech feature currently supports over 20 distinct voices, covering a wide range of tones and styles. Whether you want a male or female voice, young or elderly, we have options that will fit your project perfectly. This flexibility lets you choose the voice that best matches the character or mood of your video.
How to Use the New Features
- Visit LipSyncShow and upload your talking video as usual.
- In the audio selection step, choose between uploading an audio file, typing text for TTS, or recording your voice directly.
- If selecting TTS, browse and pick from the variety of available voices.
- Generate your lipsync video and preview the result instantly.
Why This Update Matters
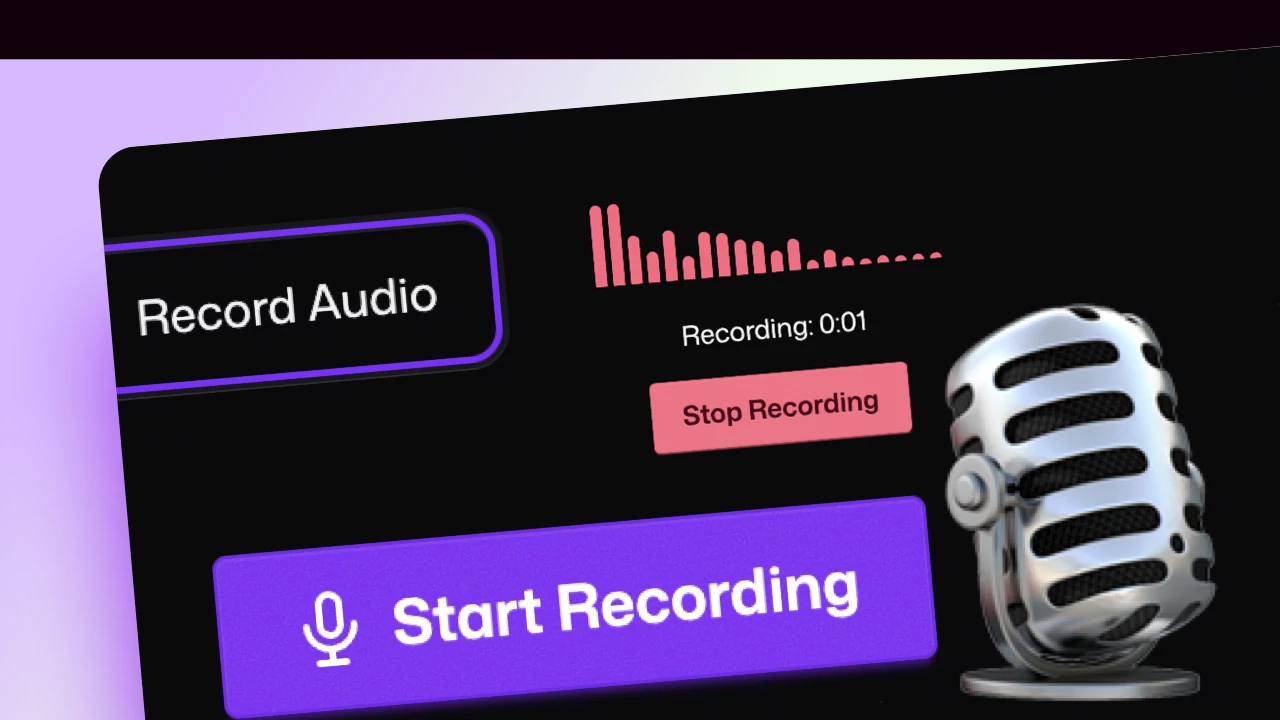
By integrating Text To Speech and recording capabilities, LipSyncShow removes barriers for users who might not have ready audio files. It enables quick content creation, experimentation with different voices, and enhances accessibility. This update reflects our commitment to continuous improvement and providing innovative tools for creators.
Try out these new features today and bring your lipsync videos to life faster and with greater creativity!
